Exporting Workbooks from Kedro with Openpyxl

ML Researcher
This post is going to walk through how to go about writing (and formatting) excel files using Kedro and openpyxl in Python. For the uninitiated, Kedro is an open-source framework for creating data-science code. This is not meant to be a comprehensive tutorial in kedro (for that see the first two references at the end of this post). However for the sake of any part of this to make sense, there are a few concepts that need to be explained.
Kedro Concepts
Kedro builds pipelines, using nodes that accepts inputs and return outputs. The inputs/outputs to these nodes which are meant to be pure python functions can be either parameters defined in yaml files or an entry in kedro's data-catalog. For example, in the following pipeline (produced using kedro-viz), we have a raw table undergoing some processing by a node named "Create Base Table" which stores its output as "Base Table":
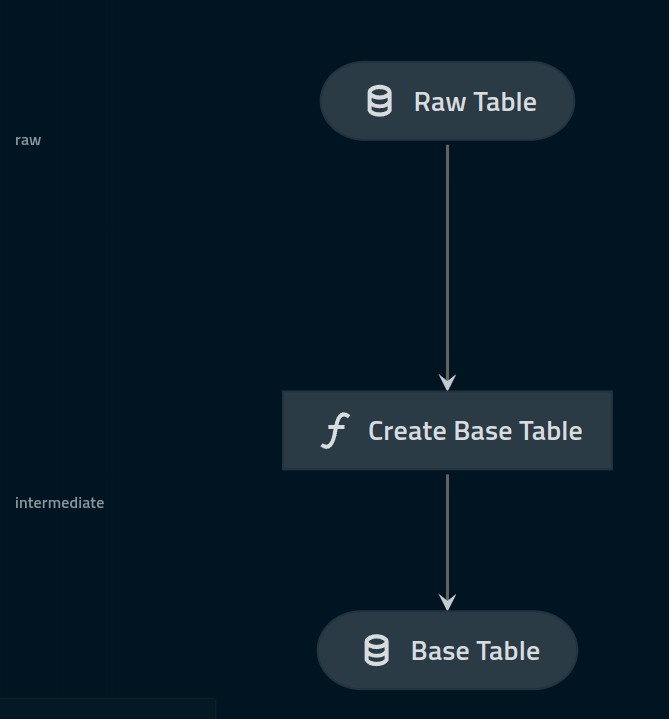
The mechanics of nodes, etc are covered in-depth in Kedro's documentation, however, there was one aspect in getting an Excel file as an output (as opposed to a parquet, csv etc) that required a slightly more nuanced approach.
When defining a data-catalog entry for kedro, (such as the Base Table above which is the output of the node), we define it as follows in yaml:
base_table:
type: pandas.ParquetDataSet
filepath: dbfs:/mnt/data/02_intermediate/base_table.pq
layer: intermediate
The above assumes that our node returns some python object which we can call pandas to_parquet function on, which then writes to disk. The "type" is a list of different datasets supported within the kedro environment. We can confirm this theory by looking at kedro's implementation of the pandas.ParquetDataSet here.
The Mechanics of the Data Catalog
The data-catalog provides an interface between python code and data, by abstracting away the mechanics of loading/saving into dataset types, stored at the specified filepath.
Each of kedro's datasets must implement the _load, _save and _describe methods, which contain instructions on how a given dataset type implements load, save and repr respectively. Kedro has a dataset to cater to writing excel files called the ExcelDataSet If we look at its _save method:
def _save(self, data: Union[pd.DataFrame, Dict[str, pd.DataFrame]]) -> None:
output = BytesIO()
save_path = get_filepath_str(self._get_save_path(), self._protocol)
# pylint: disable=abstract-class-instantiated
with pd.ExcelWriter(output, **self._writer_args) as writer:
if isinstance(data, dict):
for sheet_name, sheet_data in data.items():
sheet_data.to_excel(
writer, sheet_name=sheet_name, **self._save_args
)
else:
data.to_excel(writer, **self._save_args)
with self._fs.open(save_path, mode="wb") as fs_file:
fs_file.write(output.getvalue())
self._invalidate_cache()
we can see that this dataset uses pandas ExcelWriter to output sheets into an excel file, which assumes that the data being saves is compatible with pandas native excel implementation.
Nuances with openpyxl
openpyxl (a popular python library for formatting excel workbooks), handles writing slightly differently. Although pandas can use openpyxl as a backend for writing, things become slightly more complicated when trying to write more tailored files. openpyxl uses the concept of a workbook (analogous to an Excel workbook), with sheets. For example:
from openpyxl import Workbook
wb = Workbook() # create a new workbook
ws = wb.active # get the active sheet
# do some formatting and data insertion
ws.title = "Title One"
ws['B4'] = "2026-01-01"
ws['B5'] = 100.00
The above code creates a Workbook object and does data insertion. Naturally, we would want to export this workbook to an .xlsx file. However, if we use the mechanics defined in ExcelDataset above:
In [8]: with ExcelWriter("file.xlsx") as writer:
...: wb.to_excel(writer)
...:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-8-7575d1f1c47c> in <cell line: 1>()
1 with ExcelWriter("file.xlsx") as writer:
----> 2 wb.to_excel(writer)
3
AttributeError: 'Workbook' object has no attribute 'to_excel'
This is, upon further introspection, actually expected. The Workbook object of openpyxl does not natively support being written using pandas.ExcelWriter , and instead has its own interface using .save. (we'd gloss over its mechanics at the moment, the more important part is now creating a kedro dataset type that is compatible with writing this object).
Custom Datasets in kedro
As mentioned before, a custom dataset type in kedro must implement three methods:
_load: how to read the file_save: mechanics on determining the file-path and saving_describe: essentially what__repr__does
So to create our custom dataset which handles openpyxl workbooks, its _save method must not use pandas.ExcelWriter, but must instead call .save directly on the input data object:
from openpyxl import WorkBook, load_workbook
from kedro.io import AbstractDataSet
from kedro.io.core import get_filepath_str, get_protocol_and_path
class OpenPyxlDataSet(AbstractDataset):
def __init__(self, filepath: str):
self._filepath = filepath
def _load(self, ) -> openpyxl.WorkBook:
return load_workbook(self._filepath)
def _save(self, data: openpyxl.WorkBook) -> None:
data.save(self._filepath)
def _describe(self, ): -> None:
return dict(
filepath=self._filepath
)
Note the above lacks much of the necessary error-handling code that would make this dataset production ready.
Now, we can define a data-catalog entry (assuming our new dataset is in src/project/extras/datasets.py) as follows:
excel_workbook_dataset:
type: project.extras.datasets.OpenPyxlDataSet
filepath: data/08_reporting/excel_workbook.xlsx
layer: reporting
Finally, we can point any one of our nodes with potential openpyxl code to use the above data-catalog entry as its output.



