

This is not going to be a full explanation on the ins-and-outs of web-scraping, this post simply covers how to web-scrape data from sites which do not present all its data on page-load. A common example of this is Google Images. (Please verify whether scraping is allowed on your chosen website prior to proceeding)
Why even?
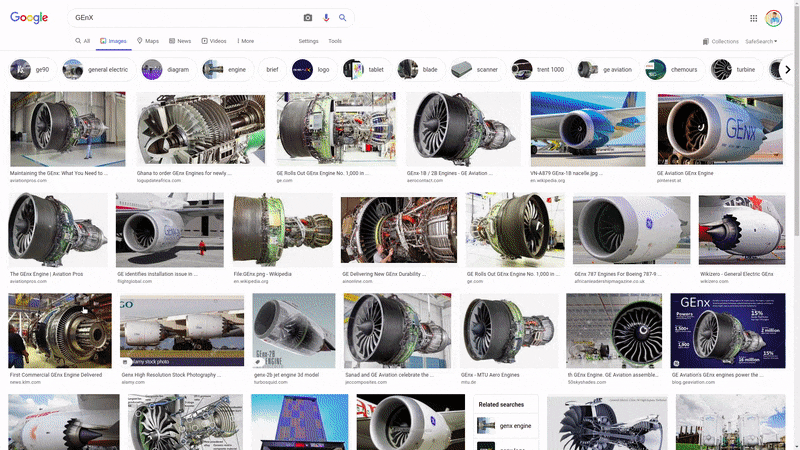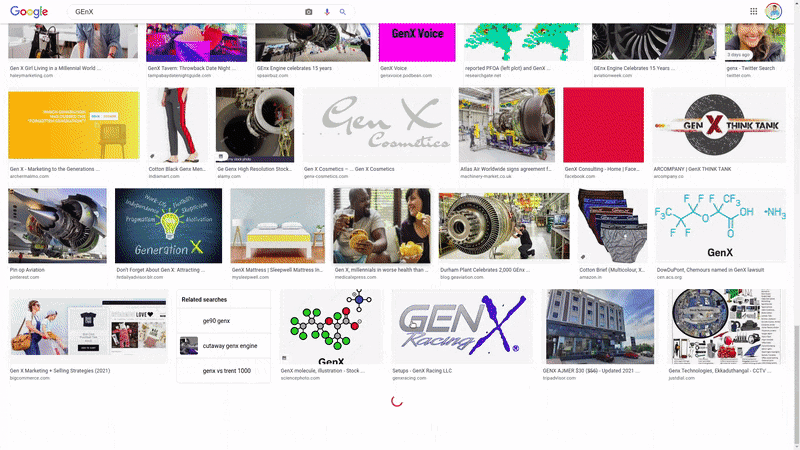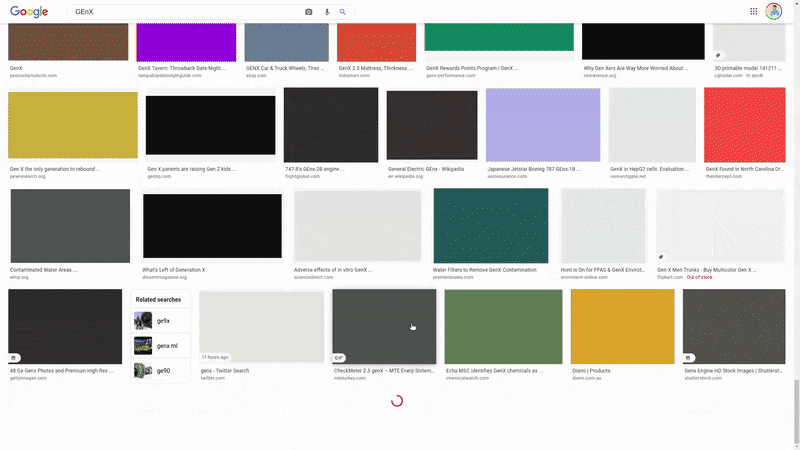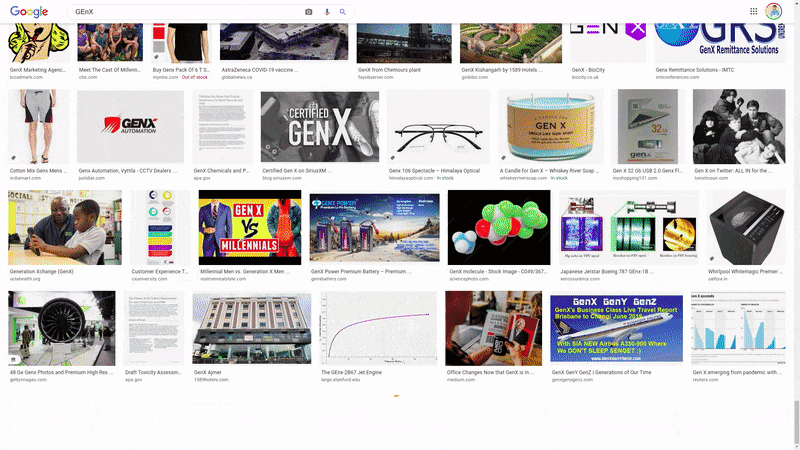 Note how when I scroll to the end, more content 'magically' appears? This is a technique used to optimize how pages load, and is quite common across newer websites. It, however poses a challenge.
Note how when I scroll to the end, more content 'magically' appears? This is a technique used to optimize how pages load, and is quite common across newer websites. It, however poses a challenge.
Say for example, that you wanted to download all the Google images results for a certain search term using a Python web-scraper, a straightforward way of doing this would be to scroll to the end of the page (thereby forcing all content to load), and then proceeding as usual to loop through the page's contents
See the following for instructions on how to get set-up with Selenium Selenium Installation
Initiating our Google Search
Once you have Selenium installed, you need to point your Python script to the driver you'd just downloaded (in this case, my driver is located in the /home/aadidev directory).
from selenium import webdriver
driver = webdriver.Chrome(executable_path= '/home/aadidev/chromedriver')
The driver object returned can then be used to navigate to a given webpage (in this case I'm using the get method to access Google Images.
driver.get('https://images.google.com')
In order to search for a given term, the driver needs to know where to place your search text. You can find this by going to Google Images, right-clicking on the search-box and clicking Inspect Element as shown below.
The window on the right then shows the highlighted HTML code corresponding the the Google search bar. Right-click on this code and click Copy -> xpath. (The X-path is a low-level method used to find elements by means of its hierarchical placement on a page, this is not really important to think about for our purpose).
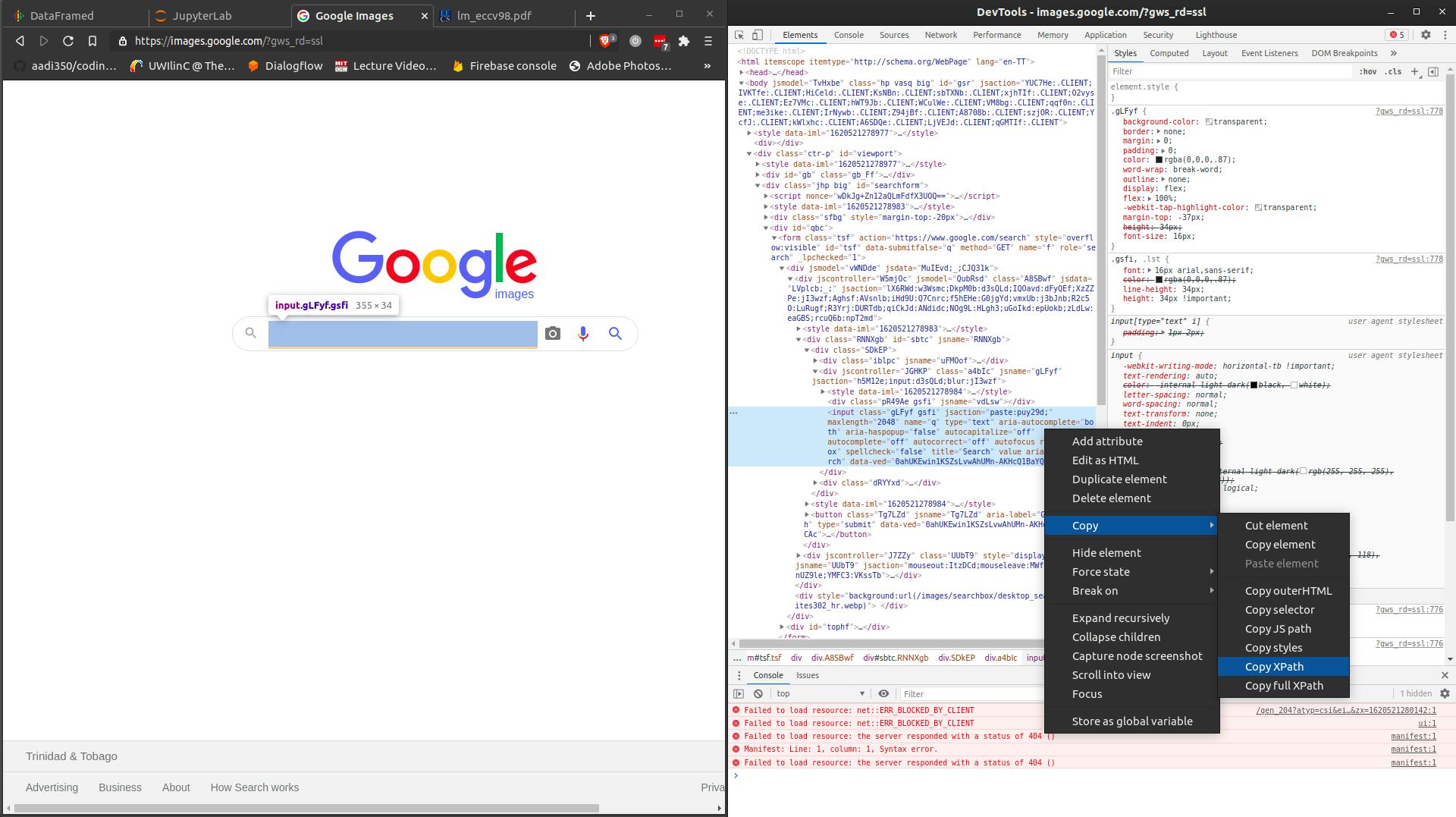
Selenium provides a few methods for finding on-page elements, the following method returns the object found from the x-path you'd just copied (the stuff in the brackets). For other purposes, Selenium also allows you to find elements by tag-name, css-selector, name and id (see the documentation above for the full API reference)
search_box = driver.find_element_by_xpath('//*[@id="sbtc"]/div/div[2]/input')
Now we can enter the search term into the search-box found (here I'm searching for the General Electric GEnX turbofan engine) using the send_keys() method. The same method is then used to click 'Enter' on the search box to initiate the Google Image search
from selenium.webdriver.common.keys import Keys
search_box.send_keys('General Electric GEnX')
search_box.send_keys(Keys.ENTER)
At this point we've successfully searched for a term on Google images and navigated to the results. Now is where the tricky part begins
Loading All the Search Results
The key to loading all the results is to scroll to the bottom of the page repeatedly. However to do this manually would completely go against the entire point of web-scraping, hence we need Selenium to do this for us.
When do we stop scrolling?
In order to figure out when to stop scrolling, we need to compare the current scroll height available to the previous scroll height, if the current scroll height of the page didn't increase, we know to exit the loop and stop scrolling.
Therefore the first thing we do is to get the current scroll height using the following line of code.
last_height = driver.execute_script('return document.body.scrollHeight')
Following this, we loop constantly scrolling to the bottom of the page, and recalculating the new height. The window.scrollTo portion of the following code starts scrolling at position 0, and ends at whatever value the scrollHeight of the given page happens to be.
This ensures that the end of the page is reached in every iteration. This however triggers the dynamic page to load more content, which in turn updates the scroll height of the current page and the process continues
while True:
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
new_height = driver.execute_script('return document.body.scrollHeight')
if the new_height is the same as the last height, we break the loop to perform any processing we may wish to perform on the full page
if new_height == last_height:
break
If the new height is not equal to the last height, we update the last height with the new height and continue the loop
last_height = new_height